Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
目录
🐶7.1 什么是分区器?
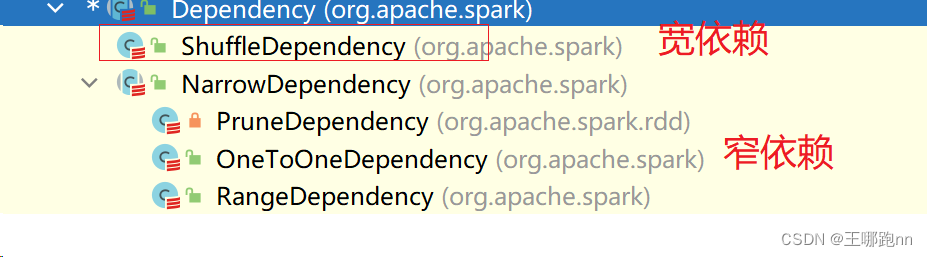
🐶7.2 RDD之间的依赖关系
🥙1. 窄依赖
🥙2. 宽依赖
🐶7.3 什么时候需要使用分区器
🐶7.4 内置分区器
1.🥙HashPartitioner(哈希分区器)
2.🥙RangePartitioner(范围分区器)
7.5 🥙自定义分区器
🐶7.1 什么是分区器?
分区器是上下游RDD分配数据的规则
🐶7.2 RDD之间的依赖关系
RDD之间存在依赖关系,可以通过RDD之间的依赖关系容错恢复 !
rdd之间的依赖关系又称为血源关系
依赖关系分两种: (根据上下游RDD之间数据的传输规则)
🥙1. 窄依赖
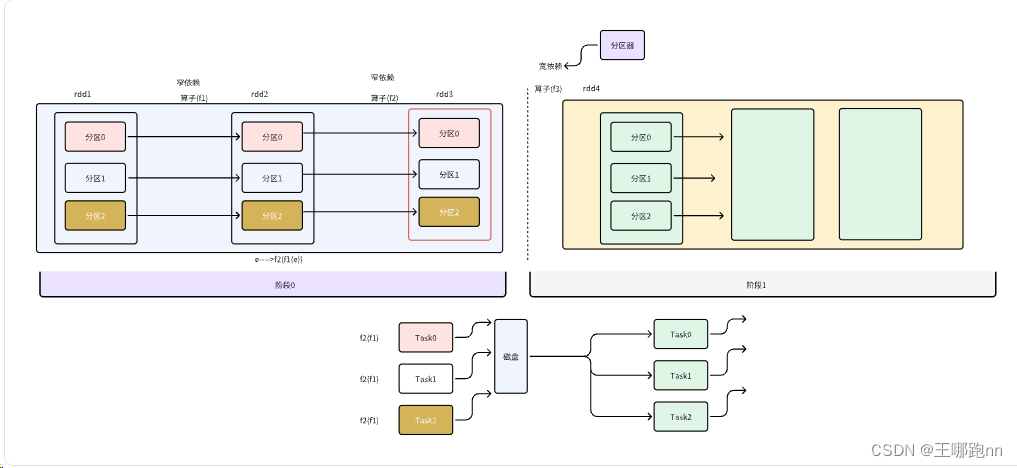
上游RDD的任意一个分区的数据只会被下游某一个分区引用
🥙2. 宽依赖
上游RDD的任意一个分区的数据可能会被下游所有分区引用 ---shuffle 需要分区器
package com.doit.day0217import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}/*** @日期: 2024/2/19* @Author: Wang NaPao* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343* @Tips: 和我一起学习吧* @Description:*/object Test04 {def main(args: Array[String]): Unit = {// 创建SparkConf对象,并设置应用程序名称和运行模式val conf = new SparkConf().setAppName("Starting...") // 设置应用程序名称.setMaster("local[*]") // 设置运行模式为本地模式// 创建SparkContext对象,并传入SparkConf对象val sc = new SparkContext(conf)val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2) // 创建一个有两个分区的RDD// 对rdd1的每个元素乘以10,这是一个窄依赖,因为每个rdd1分区的数据仅影响对应rdd2分区的数据val rdd2 = rdd1.map(_ * 10)// 过滤出rdd2中大于20的元素,这也是一个窄依赖,因为每个rdd2分区的数据仅影响对应rdd3分区的数据val rdd3 = rdd2.filter(_ > 20)// 根据元素值对rdd3进行分组,这是一个宽依赖,因为每个rdd3分区的数据可能会影响多个rdd4分区的数据val rdd4 = rdd3.groupBy(e => e)// 对rdd4的每个分区进行处理,并输出分区号和分区中的元素val result2 = rdd4.mapPartitionsWithIndex((p, iter) => {iter.map(e => p + ": " + e)})result2.foreach(println)// 关闭SparkContext对象sc.stop()}
} 
作用: RDD之间的依赖关系--宽/窄依赖
宽依赖会Shuffle , 窄依赖不会
宽依赖需要分区器 , 窄依赖不需要
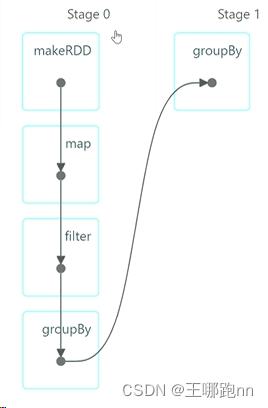
程序在执行过程中, 遇到宽依赖自动的断开任务的执行, 划分成两个阶段
程序在执行过程中 , 如果两个RDD之间是窄依赖 ,将两个RDD的计算逻辑组成算子链条
各个阶段就会以最后一个RDD的分区数创建指定个数的任务实例
阶段之间有先后关系,不同阶段对应不同的任务
🐶7.3 什么时候需要使用分区器
宽依赖,产生shuffle的时候(上游RDD一个分区的数据可能被下游RDD的所有分区引用)
🐶7.4 内置分区器
Spark 提供了几种内置的分区器,常用的包括:
1.🥙HashPartitioner(哈希分区器)
-
工作原理:
HashPartitioner根据数据的哈希值将数据分配到不同的分区中。具体来说,对于RDD中的每个键值对(K,V),HashPartitioner会调用键的hashCode方法来计算哈希值,然后取模分区数来确定该键值对所属的分区编号。因为相同键的哈希值相同,所以相同键的数据会被分配到同一个分区中。
-
优点:
-
实现简单,计算快速。
-
数据均匀分布,适用于大多数场景。
-
-
缺点:
-
当键的分布不均匀时,可能会导致分区不均匀,进而影响性能。
-
2.🥙RangePartitioner(范围分区器)
-
工作原理:
RangePartitioner适用于有序的RDD,并根据键的范围将数据分配到不同的分区中。具体来说,RangePartitioner会根据RDD的键进行排序,并将RDD划分成连续的若干个范围(range),然后将每个范围内的数据分配到一个分区中。范围的划分依据是根据目标分区数平均划分。
-
优点:
-
适用于有序数据集,能够有效地将数据按照键的范围分配到不同的分区中。
-
分区间数据分布较为均匀。
-
-
缺点:
-
对数据集的有序要求较高,可能会增加预处理成本。
-
在数据不均匀的情况下,可能会导致分区不均匀,进而影响性能。
-
7.5 🥙自定义分区器
允许用户根据自己的需求定制数据的分区规则,以满足特定的业务需求。
package com.doit.day0217
import org.apache.spark.Partitioner
/*** @日期: 2024/2/18* @Author: Wang NaPao* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343* @Tips: 和我一起学习吧* @Description:*/class MyPartitioner(p: Int) extends Partitioner {// 分区数override def numPartitions: Int = p// 变量用于轮询选择分区编号var x: Int = 0// 根据键获取分区编号的方法override def getPartition(key: Any): Int = {// 分区规则:不同的 key 返回不同的分区编号if (x == 0) {x = 1} else {x = 0}x}
}package com.doit.day0217import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}import java.sql.{DriverManager, ResultSet}
import org.apache.log4j.{Level, Logger}/*** @日期: 2024/2/18* @Author: Wang NaPao* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343* @Tips: 和我一起学习吧* @Description:*/object Test03 {def main(args: Array[String]): Unit = {// 创建SparkConf对象,并设置应用程序名称和运行模式val conf = new SparkConf().setAppName("Starting...") // 设置应用程序名称.setMaster("local[*]") // 设置运行模式为本地模式// 创建SparkContext对象,并传入SparkConf对象val sc = new SparkContext(conf)// 创建普通的 RDDval rdd = sc.parallelize(List("apple", "banana", "cherry", "date", "elderberry","a","b","c"),2)// 转换为键值对 RDD,键为字符串本身,值为字符串长度val kvRDD = rdd.map(str => (str, str.length))println(kvRDD.getNumPartitions)// 使用自定义分区器进行分区val partitionedRDD = kvRDD.partitionBy(new MyPartitioner(2))partitionedRDD.mapPartitionsWithIndex((p, iter) => {iter.map(e => (p, e))}).foreach(println)}
}